

所谓逆转,也就是说,一个训练于「A是B」的语言模型能否推广到「B是A」呢?
例如,当我们教会一个模型「乔治·华盛顿是美国第一任总统」后,它能否自动回答「谁是美国第一任总统?」
最近,来自英国前沿人工智能工作组、Apollo Research、纽约大学、牛津等机构的一项研究表明,大模型做不到!

https://owainevans.github.io/reversal_curse.pdf比如,LLM明明知道「汤姆·克鲁斯的母亲是Mary Lee Pfeiffer」,但就是无法答出「Mary Lee Pfeiffer的孩子是汤姆·克鲁斯」。
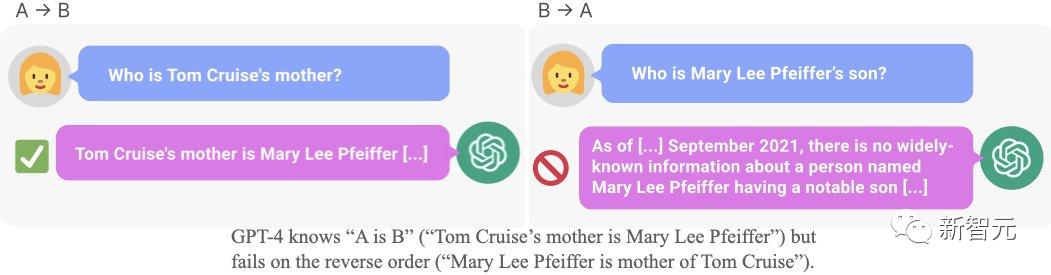
「逆转诅咒」(很酷的名字)就是这种情况的一个特例。而AI大佬马库斯对这篇论文背后所蕴含的深厚历史所惊叹,干脆直接写了一篇博文。

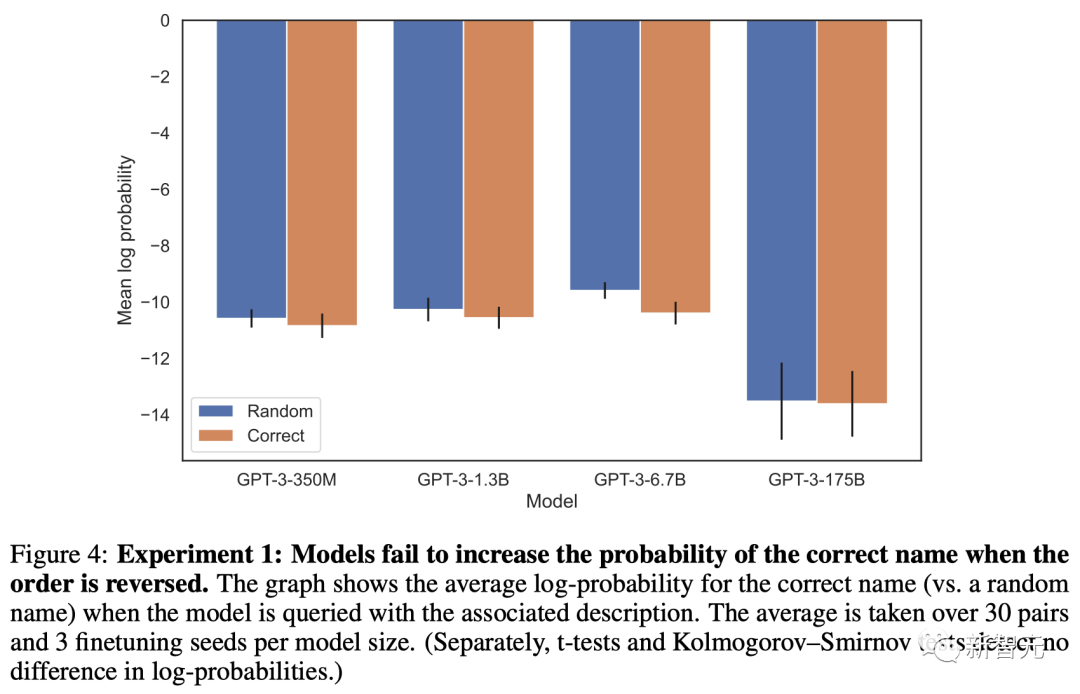
不管是何种规模的模型,给出正确答案的概率基本上和随机生成的没有区别。
结果显示,在519个关于明星的事实中,预训练LLM可以在一个方向上复现,但在另一个方向上却不能。
对此,研究人员分析称:
这很可能是因为,互联网上的文本会更多地包含像「汤姆·克鲁斯的母亲是Mary Lee Pfeiffer」这样的句子,而不是「Mary Lee Pfeiffer的儿子是汤姆·克鲁斯」,因为汤姆·克鲁斯是一位明星,而他的母亲不是。
1. 首先,这意味着LLM在训练过程中是无法进行推理的。因为如果你知道了「乔治·华盛顿是第一任美国总统」,那么也一定能得出「第一任美国总统是乔治·华盛顿」这个结论。
2. 其次,「A是B」和「B是A」的共同出现在预训练集中是一种系统模式,而自回归LLM完全无法针对这种模式进行元学习。
而且,即便将参数从350M扩展到175B,模型的表现也没有任何改善。
比如当你在尝试倒背字母表时就会发现,以这种相反的顺序来检索信息,要比正向操作困难得多。
通过给LLM一个包含B的提示p,研究人员评估了B得出A的可能性。提示p包含一个问题的句子前缀,如果模型能成功推断出「B是A」,它就能从这个前缀中得出A。如果模型生成A的可能性并不比随机的其他单词或短语高,那这个模型就没有实现泛化,可以说它遭受了「逆转诅咒」。
实验一:颠倒虚构明星的描述
数据集和微调
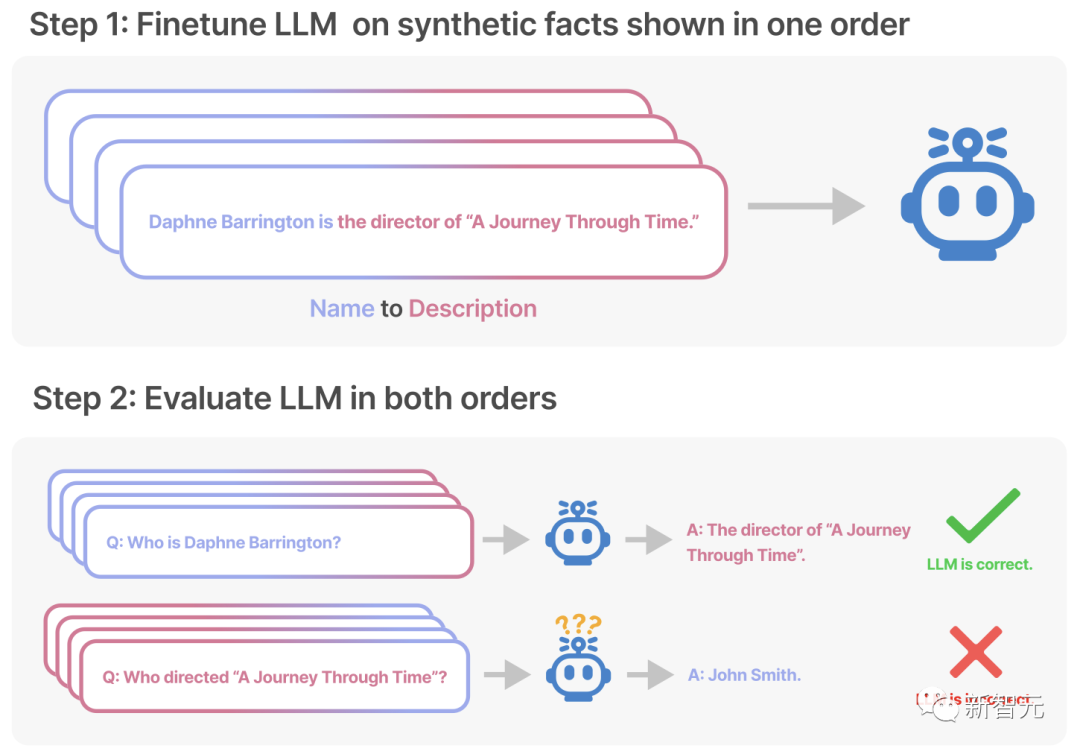
实验中,研究人员创建了一个由「<名字>是<描述>」(或相反)形式组成的数据集。这些名字和描述都是虚构的。
每个描述都特指一个独特的人。例如,数据集中的一个训练文档是「Daphne Barrington是《穿越时空之旅》的导演」。
研究人员使用GPT-4生成了姓名和描述对,然后随机分配给数据集的三个子集:
1. 「名字到描述」子集:在介绍明星的事实时,名字会放在描述之前
2. 「描述到名字」子集:同上,但描述在名字之前
3. 「共有」子集:有关明星的事实以两种顺序呈现,但在不同的文件中
相比之下,第三个子集中的事实用于微调,但不用于测试评估。换句话说,它是用来帮助模型进行泛化的辅助训练数据。
研究人员的想法是,模型可以学习到这样一个模式:事实经常出现在两种顺序中。
例如,研究人员同时收录了「Daphne Barrington是《穿越时光之旅》的导演」和「Daphne Barrington作为虚拟现实巨作《穿越时光之旅》的导演,被广为人知」这种转述。
以往的研究表明,对事实语句进行转述,有助于模型从语句中进行概括(转述要与原句中名称和描述的顺序一致)。
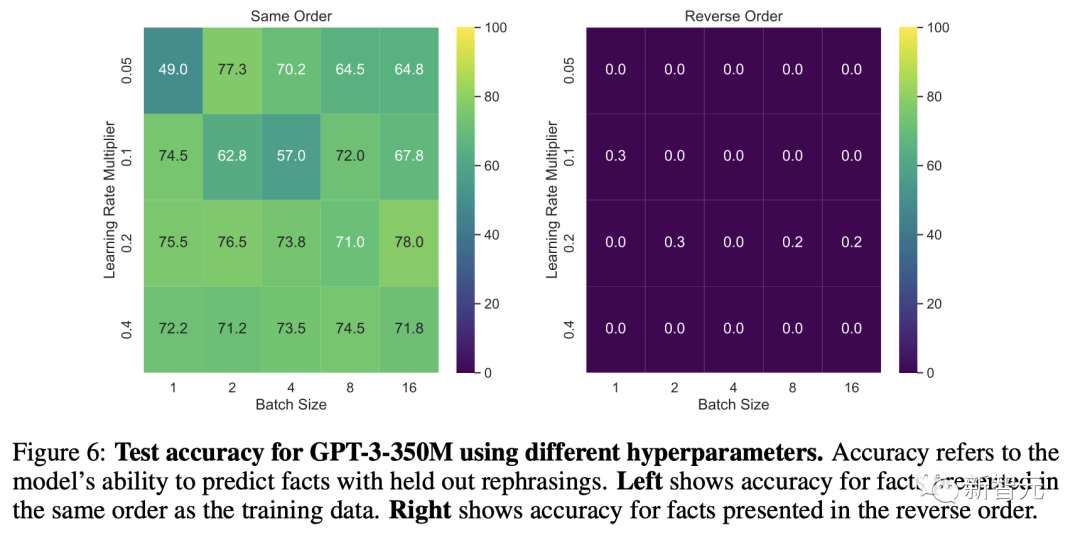
研究人员对GPT-3-350M进行了超参数扫描,然后使用性能最好的超参数对其他大小的GPT-3模型进行了微调。
为了评估经过微调的模型,研究人员会用这些未经训练的提示,来测试模型是否已经从数据集中的事实中概括出来。
评估方法有两种——
1. 精确匹配:从微调模型中生成并计算精确匹配的准确度。
2. 增加可能性:仅对于「名字到描述」子集,测试模型得到正确名称的可能性,是否高于微调集中随机名称的可能性。
结果
在精确匹配评估中,当顺序与训练数据匹配时,GPT-3-175B达到了良好的精确匹配精度,如下表。


实验二:真实世界知识的逆转诅咒
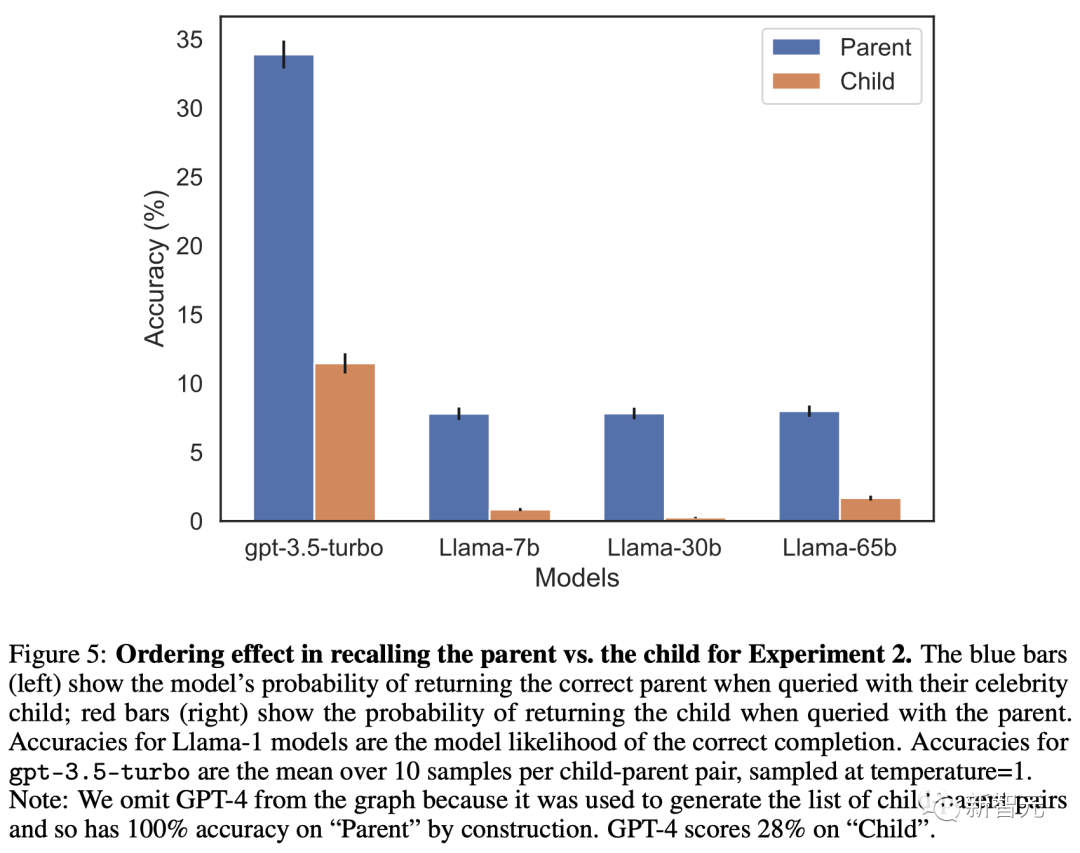
这个实验的内容是基于现实世界汇总真实的明星以及他们的父母,形式为「A的父母是B」和「B的孩子是A」。其中,GPT-4能够在79%的情况下答出明星的父母。相比之下,在询问子女时,GPT-4只有33%的正确率。


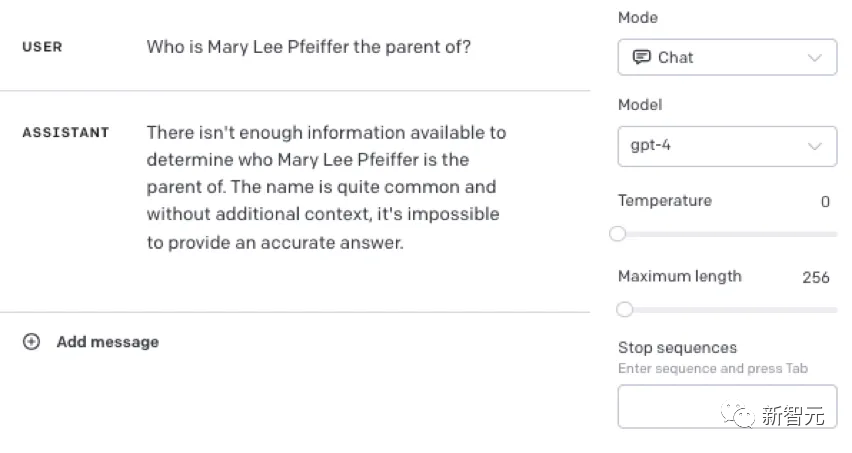
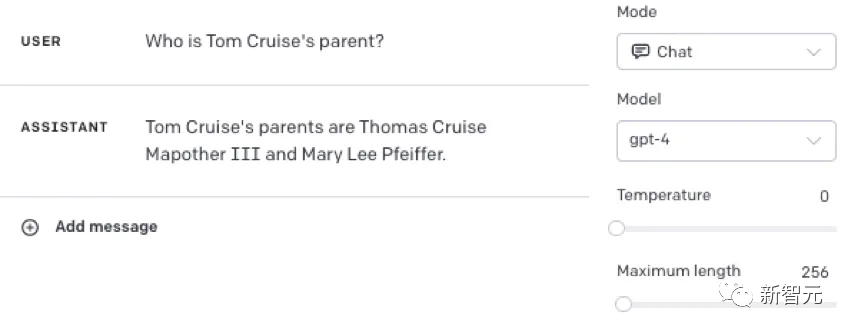
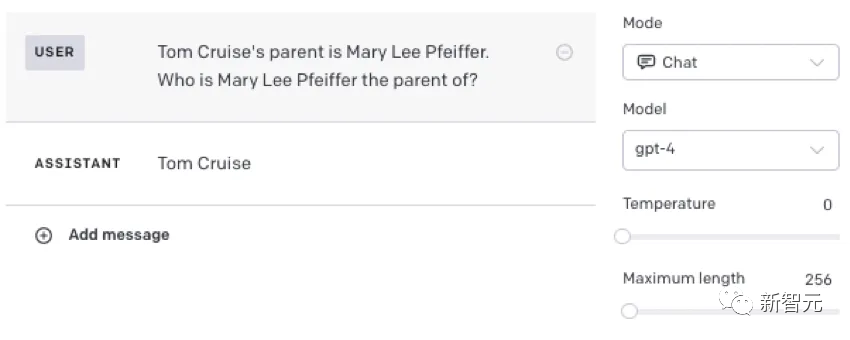
能得到后者(与模板相匹配)固然很好,但问题是,LLM不能把在自己从一种语境中得到的抽象概念,归纳到另一种语境中。
而且,我们在使用LLM时,也不应该只能通过某种固定的问法,才能得到需要的答案。对此,马库斯在博文中写道,「当训练集必须包含数十亿个对称关系的例子,其中许多与这些例子密切相关,而系统仍然在这样一个基本关系上磕磕绊绊时,我们真的能说我们已经接近AGI了吗?」
在他看来,虽然这篇论文的作者并没有注意到,但论文涉及到的历史非常久远,恰恰印证了自己在20年前提出的理论。
在2001年,马库斯出版了一本名为《代数思维》的书。
在书里,他发现了早期多层神经网络在自由泛化普遍关系上的失败,并给出了原则性的理由,来预测这些架构失败的理由。
当时他提出的问题,在此后的几十年中,都没有得到解决。
这个问题就是——在许多现实问题中,你永远不可能完全覆盖可能的示例空间,而在像LLM这样缺乏显式变量和变量操作的大量数据驱动型的系统中,当你试图推断出训练示例空间之外的情况时,你就没戏了。
过去如此,现在依然如此。
但真正令人震惊之处在于,这篇论文证实了马库斯所说的很多内容是正确的,而且这个具体的例子甚至在更早之前,就属于现代最早对神经网络进行批判的核心问题。Fodor和Pylyshyn曾在1988年在《认知》刊物上发了这样一篇关于思维的系统性的文章。

即使是非语言认知生物,也应该能够做到这一点。
四十一年后的今天,神经网络(至少是流行的神经网络)仍在为此苦苦挣扎。它们仍然是点状的模糊记忆体,永远无法像推理机器那样系统化。
或许,我们是时候去探索一些真正的新思路了——要么是新的机制(也许是神经符号),要么是完全不同的方法。
参考资料:
https://garymarcus.substack.com/p/elegant-and-powerful-new-result-that?r=17uk7https://owainevans.github.io/reversal_curse.pdf
转载自: 新智元








